Stable Diffusion Image Prompt is your ally if you seek a dynamic, controlled, and multimodal approach to impact the creative output of text-to-image diffusion models.
It acts as a bridge connecting textual and visual prompts, fostering a harmonious interplay.
So, before delving into how to use image prompts, let’s get a brief introduction about it.

What is Stable Diffusion Image Prompt?
Stable Diffusion Image Prompt is a feature or tool that enables you to incorporate images into a prompt, influencing styles, and colors. You can use image prompts alone or with text prompts—explore blending images with diverse styles for the most thrilling outcomes.
When you add it with text prompts, it lets you have precise creative control, and guide dynamic generation for detailed and personalized images.
So, now let’s set up…
Set Up of Image Prompt in Automatic1111
Now let’s see the requirements and basic setup to get the ControlNet IP Adapter in Automatic 1111.
Step 1: Obtain IP Adapter Files
Head over to the Hugging Face and snag the IP Adapter ControlNet files from the provided link.
Opt for the .safetensors versions of the files, as these are the go-to for the Image Prompt feature, assuming compatibility with the ControlNet A1111 extension.
2. Download ControlNet Models:
Navigate to the individual ControlNet model and download that you require.
Save these models in the designated directory: “stable-diffusion-webui\models\ControlNet\”.
3. File Format Adjustment:
If you downloaded any models with a .bin extension, change the file extension to .pth.
This ensures compatibility with the required file format for the Image Prompt feature.
That’s it, your system is ready to generate high-quality outputs based on the image prompt.
How to Use Image Prompt in Automatic 1111
Before starting, check the extensions tab to confirm your ControlNet extension is updated for compatibility with acquired IP Adapter files and ControlNet models.
Start with text-to-image
To test the IP Adapter’s effects, begin with text-to-image without ControlNet’s IP adapter.
For this, I am using the following parameters and prompts.
Prompt: RAW photo of a woman, 8k, DSLR, high quality.
Negative prompt: Blurry, unrealistic, cartoon, anime, low quality, error, bad anatomy, bad color.
Model: AbsoluteRealityV181
Image Width: 576, and Height: 864
Scale: 7, Steps: 25, Sampler: Euler a
So, the generated image:

Add Image Prompt Using IP adapter
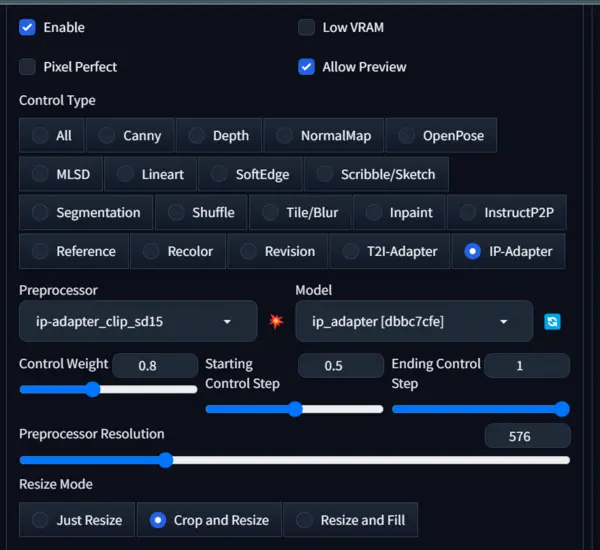
Now, ensure the settings match the image above and below. I am using Stable diffusion safetensors models for this test.
Enable: Yes, and Pixel Perfect: No
Control Type: IP-Adapter
Preprocessor: ip-adapter_clip_sd15
Model: ip-adapter_sd15
Control Mode: Balanced
Resize mode: Crop and Resize
Now, upload an image in the ‘Single Image (IP-Adapter)’ canvas to serve as the image prompt and hit the generate button.


The image is generated with Control Weight 1 and Starting Control Step 0, and you can see the image is not satisfactory.
No, let’s try another setting and generate:


Here, CW= Control Weight and SCS= Starting Control Steps.
The images are good but do not accurately reflect the uploaded image style.
I also tested all the possible values of CW and SCS but the results are very bad so now let’s move to IP- Adapter plus.
Give a Try to IP-Adapter Plus
Keep all the parameters and settings the same; simply change the model from ip-adapter_sd15 to ip-adapter_plus_sd15, and then click the generate button.

Wow, the image almost mirrors the uploaded image with the IP-Adapter Plus model and CW=1 & SCS=0.
I have also tested all the possible values of CW and SCS with IP-Adapter Plus, but the images did not meet my desire. You also can check it from your end.
Now, let’s explore the SDXL Model,
Check SDXL Model:
Before commencing the process, ensure you have switched your primary text-to-image model from SD to SDXL.
In my case, I am using dreamshaperXL10. Now, using the same prompt and negative prompt, generate the below image:

Now, maintain the same settings for ControlNet; only modify the following:
Processor: ip-adapter_clip_sdxl
IP-Adapter Model: ip-adapter_xl [4209e9f7]
Must use a square image size otherwise the generated image may go out of frame.


You can observe that the images slightly reflect the style of the uploaded image, particularly showcasing accurate mirrors of the face and age.
After numerous experiments with various adjustments, I have concluded that the optimal IP-Adapter model is IP-Adapter Plus with CW=1 & SCS=0.
Therefore, don’t waste your time if you intend to emulate a style using the image prompt in automatic1111.
So, what’s the solution?
Yes, I found a fix, and it’s using Foocus Stable Diffusion WebUI’s Image prompt.
That’s why I will now utilize it to demonstrate all the use cases of the image prompt in Stable Diffusion.
You May Also Like: Stable Diffusion Prompt Grammar
When to Use Image Prompt in Stable Diffusion:
We find some uses of the image prompt listed below from our experiences, but instead, you may apply these to more concepts.
1. Repeated Image Generation:
Suppose you have an image that you want to use as a model. You can seamlessly blend visual cues for a dynamic creative process without any need for text prompts.
If you don’t have the Fooocus Stable Diffusion WebUI, don’t worry.
I will provide you with the Google Colab notebook at the end of the article, which you can use for free.
Now, let’s see the process:
After opening the WebUI, scroll down and click on “Image Prompt” to upload your image as shown in the below image.
You can adjust the style, aspect ratio, negative prompt, and more in the advanced options.
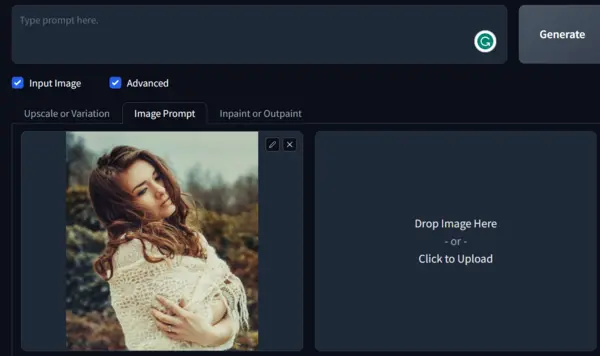
Now, hit the generate button without any text prompt.

Isn’t the image superior to the one generated by the IP-Adapter? I certainly hope so.
2. Want to Replace the Main Model:
Now, if you desire the same style and pose for a male character, simply type “Male” in the prompt box and click on generate.

The dress and background are copied, but the hand position is not reflecting accurately. You can adjust it from your end by tweaking the settings.
3. Blend Multiple Images:
Upload two images to merge them.
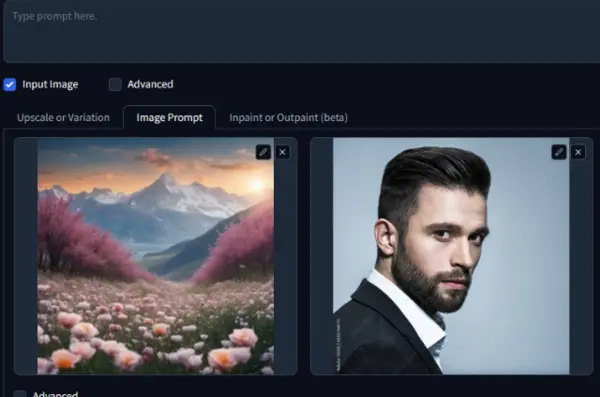
Adjust the setting and hit the generate button without a text prompt.

4. Blend Multiple Styles:
Upload the styles in the image canvas 1 and 2.
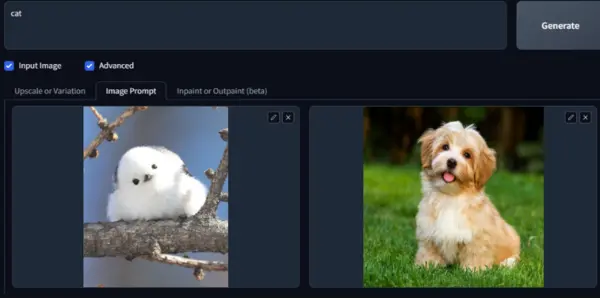
Now, determine which character should have the styles applied. Write the character’s name in the prompt box and click on generate.

You can see both styles applied to the character Cat. If you want to learn more about this, you can read the GitHub discussion on the image prompt.
Final Verdict:
I hope you agree with me that the Fooocus image prompt is superior to automatic1111. If you want to use it, you can find the Google Colab notebook.
Simply run it, and you’ll receive a link as shown below.
Click it, and your Fooocus WebUI will be ready for experimentation.
Please note that this is not my Colab notebook; I found it on YouTube.
If there’s anything I’ve missed, please let me know by commenting below.

Hi there! I’m Zaro, the passionate mind behind aienthusiastic.com. With a background in Electronics Science, I’ve had the privilege of delving deep into AI and ML. And this blog is my platform to share my enthusiasm with you.